主成分分析(PCA)の数学的な理論とPythonによる実装¶
- Author: Yuki Takei (noppoMan)
- Github: https://github.com/noppoMan
- Twitter: https://twitter.com/noppoMan722
- Blog: https://note.com/noppoman
これは、noteの主成分分析の背景にある数学理論の話(最適化問題)の本文です。
主成分分析の数学的な理論の理解に必要な知識¶
主成分分析は、アルゴリズム的な観点で見るとデータの分散を最大化させる最適化問題であり、その理論は数学(とくに微分学、線形代数)により与えられている。以下は、主成分分析で使われる数学の分野をざっくりとリストしたものである。
- データ分析
- 分散、共分散
- 解析学
- 多変数関数の微分
- 陰関数定理
- 勾配ベクトル
- ラグランジュの未定乗数法(制約付き最適化問題)
- 線形代数
- ベクトル空間、計量ベクトル空間
- 実対称行列の固有値・固有ベクトル、対角化
主成分分析はこのように、多くの高度な数学理論の上に成り立っている。主成分分析を完成されたツールとして使う分には、線形代数の知識だけで事足りるのだが、それを裏付ける理論を知るにはここで上げた解析学、特にラグランジュの未定乗数法と呼ばれる制約付き最適化問題の理解が必須である。(それを支える理論として、多変数関数の微分、陰関数定理、勾配ベクトルがある。)この資料では、主にこのラグランジュの未定乗数法がどのように主成分分析で利用されているかということを主題とする。その後、今回得た知識を持って主成分分析をPythonを使って実装することを試みる。なお、データ分析の初歩や線形代数に関しては知っているものとして話を進める。
また、ここで紹介する理論は、SVMやディープラーニングでも使われているので、主成分分析以外の最適化問題を考える上でも非常に有用な理論となる。(むしろそのように読めばモチベーションが上る人もいるのではないだろうか)
ラグランジュの未定乗数法のための数学の道具¶
まずはラグランジュの未定乗数法の理解のために、次の3つの概念について見ていく。
注意: ここで取り上げるものは厳密性に欠るものもある。解析学の厳密性を持ち出すと、PCAの数学理論に行き着く前にそっとこの資料を閉じてしまう懸念がある..よって、PCAの背景にある考え方が伝わることを第一にほどほどに厳密に解説を進める。
以降、小文字アルファベットをローマン体+太字$\bm{x}$のように書いたものを$n-dim$列ベクトルとする。
陰関数¶
多変数関数 $F(x_1, x_2, \cdots, x_n)$が与えられたとする。一般に、変数$x_1, x_2, \cdots, x_n$との間に方程式$F(x_1, x_2, \cdots, x_n) = 0$があるとき、つまりある変数$x_r \hspace{5pt} (1 \leq r \leq n)$を残りの変数とある関数$f(\bm{x})$により、$x_r = f(\{x_i\}) \hspace{5pt} (i \neq r)$ と表せる時、$x_r$を$F(x_1, x_2, \cdots, x_n) = 0$によって定まる陰関数という。ただし、$x_r$は必ずしも関数とは限らない。その代表的な例を述べる。
単位円を定める方程式$x^2 + y^2 = 1$のグラフは、$F(x, y) = x^2 + y^2 - 1= 0$を満たす点全体の集まりである。一般に、$F(x, y) = 0$を満たす点$(x, y)$を零点といい、この零点の集合を$F$の零点集合という。零点集合は集合の記号で以下のように表せる。
$$ Z = \{ (x, y) \in \mathbb{R}^2 | F(x, y) = 0 \} $$これは、n変数に拡張しても同様である。また、ここで一度関数の定義を復習しておく。次のように$f: x \mapsto y$と$x$に対しただひとつ$y$が定まる$f$を関数あるいは写像といった。
さて、$F(x, y) = x^2 + y^2 - 1= 0$を満たす零点を考えよう。まずはおもむろに$x = 0$を$F$に代入すると、$F(0, y) = 0$を満たす$y$は$y = \pm 1$となる。しかし、上で述べた関数の定義より$x$に対して$y$が正負の2つの値を取ることにより、これを関数と呼ぶことはできないのである。
では、この$F$のうち対象となる領域$D$を$D = \{ (x, y) \in \mathbb{R}^2 | y \geq 0 \}$に限定すれば、$D$上で$F(x, y)$の零点集合は$\{ (x, y) \in \mathbb{R^2} | -1 \leq x \leq 1, y = \sqrt{1 - x^2}\}$で表すことができる。同様に、$y = - \sqrt{1 - x^2}$とすれば下半反面に関して、$y$を$x$の関数として表すことできる。このように、$F(x, y) = 0$が与えられ、$y = f(x)$が関数になる時、$y$を$F(x, y) = 0$で定められる($x$に関する)陰関数と呼べるのである。もちろん、$x$を$y$で表すしてもよい。
名前の由来としては、ある限定的な条件において関数になる、あるいは普段は隠れているという意味で、陰関数と呼ばれているのであろう。逆に$y = f(x)$と表されるものを陽関数と呼ぶ。
陰関数定理¶
ここまでで陰関数について学んだが、一般的に$F(x, y) = 0$が$y$あるいは$x$について解けるか否かを判定するのは容易ではない。しかし、具体的な陰関数が定まらなくても、陰関数の存在および、その微分可能性を示すための十分条件として次の定理が知られている。
定理. 2変数関数の陰関数定理¶
開集合$D \in \mathbb{R}^2$で定義された$C^1$級の関数$F: D \to \mathbb{R}$がある。$D$の点$(a, b)$において、$F(a, b) = 0$かつ$\frac{\partial F}{\partial y} \neq 0$ならば、$a$を含む開区間$I$と$I$上に定義された関数$y = f(x)$が存在し
- $b = f(a)$
- $f(x)$は$F(x, y) = 0$が定める陰関数
- $x_0 \in I, |y_0 - b| < \epsilon \hspace{2pt} (\epsilon > 0)$かつ$F(x_0, y_0) = 0 \Longrightarrow y_0 = f(x_0)$
が成り立つ。この時、$f(x)$も$C^1$級で、$\forall x \in I$に対し
$$ \begin{equation} \label{equation: implicit-1} f'(x) = - \frac{ \frac{\partial F}{\partial x} (x, f(x)) }{ \frac{\partial F}{\partial y} (x, f(x)) } \end{equation} $$なお、$F(x, y)$が$C^r$級ならば、$f(x)$も$C^r$級である。
条件3.を補足すると、$x = x_0$が$a$の近傍にあるとき、$y$についての方程式$F(x, y) = 0$は$b$の$\epsilon$-近傍$y = y_0$において、$y = f(x)$として一意に定まる と言っている。($y_0, x_0$は$I$上にある固定された実数で、その範囲は$\epsilon$に依存する)
この定理は、ラグランジュの未定乗数法において、極値判定をするための非常に重要な定理になる。(テイラー展開における平均値の定理のような立ち位置である)なので、陰関数表示された多変数関数$F = 0$がいくつかの条件を満たすことで、$F$上の点$A$における接線の傾きを(ある程度)素早く導出できる定理があるというくらいには覚えておこう。
なお、陰関数定理の証明は易しくないので割愛するが、後半の$f'(x)$の導出に必要な概念を補足し、その後に実際の陰関数定理における$f'(x)$の導出を行う。導出には連鎖律を用いるので、忘れてしまったという人は以下で復習すると良い。
補足: $f'(x)$の導出 - 連鎖律¶
高校数学で、合成関数の微分を行う時は、連鎖律と呼ばれる微分の性質を利用していた。それは、合成関数の微分は合成関数を構成する各関数の微分の積により表現できるというものである。
例として、$z = (x + a)^2 \hspace{5pt}(aは定数)$の微分に関して、$t = x + a, \hspace{5pt} z = t^2$とすれば$z$を$x$で微分したものは
$$ \frac{dz}{dx} = \frac{dz}{dt}\frac{dt}{dx} $$の形に表される。連鎖律を使い、$z$を$x$で微分すれば、$\frac{dz}{dt} = 2t, \hspace{5pt} \frac{dt}{dx} = 1$より、$\frac{dz}{dx} = 2t \cdot 1 = 2t$となり、$t = x + a$を代入して、$\frac{dz}{dx} = 2(x + a)$が得られる。これは、$(f(g(x)))' = f'(g(x))g'(x)$で知られるものである。1変数に限るが、これを$n$個の関数の合成に拡張すれば原理としては以下になる。
$$ \begin{eqnarray*} &f_1' &=& f_1' \\ &(f_2 \circ f_1)' &=& (f_2' \circ f_1) \cdot f_1' \\ &(f_3 \circ f_2 \circ f_1)' &=& (f_3' \circ f_2 \circ f_1) \cdot (f_2' \circ f_1) \cdot f_1' \\ &\vdots \\ &(f_n \circ \cdots \circ f_1)' &=& (f_n' \circ \cdots \circ f_1) \cdot (f_{n-1}' \circ \cdots \circ f_1) \cdots (f_2' \circ f_1) \cdot f_1' \end{eqnarray*} $$このように、連鎖律は微分を外側から内側に伝搬させ、それらを(積で)連結する手法と考えてよい。これを考慮して、多変数関数での連鎖律を考えよう。
2変数の関数$f(x, y)$に$x = \varphi(u), y = \psi(u)$を合成して新たに名前付けをした関数$F(u) = f(\varphi(u), \psi(u))$が$u$で微分可能であるとする。(同様に、$\varphi(u), \psi(u)$も$u$で微分可能)このとき、$\frac{dF}{du}(u)$は
$$ \frac{dF}{du}(u) = \frac{\partial f}{\partial x}(\varphi(u), \psi(u))\frac{d\varphi}{du}(u) + \frac{\partial f}{\partial y}(\varphi(u), \psi(u))\frac{d\psi}{du}(u) $$となる。このように、多変数関数における連鎖率律は$F$を全微分をして得た項にそれぞれ従属変数の微分を連鎖するような形になる。($x, y$は共に$u$の関数なので、双方を微分する必要があり、結果的に全微分を行うことになる。左辺の$du$を無限小とすれば、それは$F$の全微分の式になることも分かる.)
これをもう少し見やすい形に整理すると、
$$ \frac{dz}{dt} = f_x\frac{dx}{dt} + f_y\frac{dy}{dt} = \frac{\partial z}{\partial x}\frac{dx}{dt} + \frac{\partial z}{\partial y}\frac{dy}{dt} $$あるいは
$$ (f(\varphi(t), \psi(t)))' = f_x(\varphi(t), \psi(t))\varphi'(t) + f_y(\varphi(t), \psi(t))\psi'(t) $$のように2変数関数の合成関数の偏導関数の公式が導かれる。
(余談であるが、この連鎖律はディープラーニングにおいて、バックプロパゲーションを行うために利用される)
では、陰関数定理における式$(\ref{equation: implicit-1})$の導出に戻る。補足で導入した連鎖律(上の方)を適用し、$F(x, f(x)) = 0$を$x$で微分する。まず、左辺は
$$ \frac{dF}{dx}(x, f(x)) = F_x(x, f(x))\frac{dx}{dx} + F_{f(x)}(x, f(x))\frac{df}{dx} = F_x(x, y) + F_y(x, y)\frac{df}{dx} $$となる。右辺は$0$より、$x$で微分しても$0$である。よって、
$$ F_x(x, y) + F_y(x, y)\frac{df}{dx} = 0 $$この方程式を$\frac{df}{dx}$について解けば
$$ \frac{df}{dx}(x, y) = - \frac{F_x(x, y)}{F_y(x, y)} = - \frac{ \frac{\partial F}{\partial x} (x, f(x)) }{ \frac{\partial F}{\partial y} (x, f(x)) } $$あるいは(連鎖律の補足の下の方の式で)
$$ \begin{eqnarray*} F'(x, f(x)) &=& F_x(x, y)x' + F_y(x, y)f'(x) \\ &=& F_x(x, y) + F_y(x, y)f'(x) \end{eqnarray*} $$右辺を$f'(x)$について解けば、
$$ f'(x) = - \frac{F_x(x, y)}{F_y(x, y)} = - \frac{ \frac{\partial F}{\partial x} (x, f(x)) }{ \frac{\partial F}{\partial y} (x, f(x)) } $$が導かれる。$\frac{df}{dx} = f'(x)$となることも確認できる。
例. 陰関数定理による$f$と$F$の点$A$における接線の方程式が一致することの確認¶
陰関数定理に慣れるために、$f$と$F$の点$A$における接線の方程式が一致することを確認しよう。
曲線C:$F(x, y) = 0$が微分可能であるとする。$C$上の点$A(x_0, y_0)$における接線を求めることを考える。このとき、点Aの近傍で$F(x, y) = 0$によって定まる陰関数$y = f(x)$が存在する. $\Longrightarrow$ 点Aにおける曲線の接線と点$A$における$y = f(x)$の接線が一致する
このことを示す。
$F(x, y) = 0$が陰関数定理を満たし、$(x_0, y_0)$において
$$ f'(x_0) = - \frac{F_x(x_0, y_0)}{F_y(x_0, y_0)} $$が得られていると仮定する。$y = f(x)$の$x = x_0$における接線は、(接線の公式より) $y - y_0 = f'(x_0)(x - x_0)$ である。一方、2変数関数の接平面の方程式は
$$ F_x(a, b)(x - a) + F_y(a, b)(y - b) = 0 $$で与えられた。
よって、$a, b$を$x_0, y_0$とすれば$F_x$の点$A$における接線の方程式は$F_x(x_0, y_0)(x - x_0) + F_y(x_0, y_0)(y - y_0) = 0$となる。$F_x(x_0, y_0)(x - x_0)$を右辺に移行して両辺を$F_y(x_0, y_0)$で割れば
$$ \begin{eqnarray*} y - y_0 = -\frac{F_x(x_0, y_0)}{F_y(x_0, y_0)}(x - x_0) \\ \Longleftrightarrow y - y_0 = f'(x_0)(x - x_0) \end{eqnarray*} $$が得られ、点𝐴における$F$と$f$の接線の方程式が一致した。
陰関数定理の(3次以上の)多変数への拡張¶
ここまでで紹介した概念は、一見主成分分析に関係ないように見える。しかし、主成分分析とは、データの分散が最大となる軸を見つけるという最適化問題であるということを考慮すると、陰関数定理により、目的関数のある点$A$における接線の傾きが求まるというのは、目的関数の極値を求める準備ができたと言い換えることができる。だが、その準備はまだ完全ではない。なぜなら、主成分分析が威力を発揮するのは、人間の認識が難しくなる高次元におけるデータ分析であるからだ。したがって、より高次の多変数関数$F(x_1, \cdots, x_n) = 0$の接線の傾きを調べる必要が出てくる。このようなことから、陰関数定理を一般の多変数へ拡張することを考えていく。
$\bm{x} = (x_1, \cdots, x_n) \in \mathbb{R}^n, \bm{y} = (y_1, \cdots, y_n) \in \mathbb{R}^m$の関数$F(\bm{x}, \bm{y}) = (f_1(\bm{x}, \bm{y}), \cdots, f_m(\bm{x}, \bm{y}))$がある。このとき、$\bm{y}$について$F(\bm{x}, \bm{y}) = 0$を解くことを考えよう。なお、イメージしやすいように、$F(\bm{x}, \bm{y}) = 0$は次のように連立表示して考えることもできる。
$$ \begin{cases} f_1(x_1, \cdots, x_n, y_1, \cdots, y_m) \\ f_2(x_1, \cdots, x_n, y_1, \cdots, y_m) \\ \vdots \\ f_m(x_1, \cdots, x_n, y_1, \cdots, y_m) \end{cases} $$よって、2変数のときと同様に$y_i = g_i(\bm{x})$となるような$(g_i)(\bm{x}) = G(\bm{x})$の存在を示すことが多変数関数における陰関数定理と言える。まずは2変数における陰関数定理の定義を真似して、これを多変数に拡張してみる。
開集合$D \in \mathbb{R}^{n+m}$で定義された$C^1$級の関数$F: D \to \mathbb{R}^m \hspace{5pt}$がある。$D$の点$(\bm{a}, \bm{b} ) \hspace{5pt} \bm{a} \in \mathbb{R}^n, \bm{b} \in \mathbb{R}^m$において、$F(\bm{a}, \bm{b}) = 0$かつ$F_y(\bm{a}, \bm{b}) \neq 0$を仮定すれば、
- $b_i = g_i(a_1, \cdots, a_n) \hspace{5pt}$
- $g_i(\bm{x})$は$F(\bm{x}, \bm{y}) = 0$が定める陰関数
- $(\bm{a}, \bm{b})$の$\epsilon$-近傍$U$において、$\bm{x} \in U$に対し$f_i(x_1, \cdots, x_n, g_1(x_1, \cdots, x_n), \cdots, g_m(x_1, \cdots, x_n)) = 0 \quad (1 \leq i \leq m) \quad \Longrightarrow y_i = g_i(\bm{x}) $
となる$g_i$が存在する。では$\frac{\partial G}{\partial x_j}(\bm{x})$を求めていこう。2変数の陰関数定理同様$f_i$を$x_j \hspace{5pt} (1 \leq j \leq n)$で微分すれば
$$ \begin{eqnarray*} \frac{\partial f_i}{\partial x_j}(\bm{x}, G(\bm{x})) + \frac{\partial f_i}{\partial g_1}(\bm{x}, G(\bm{x}))\frac{\partial g_1}{\partial x_j}(\bm{x}) + \cdots + \frac{\partial f_i}{\partial g_m}(\bm{x}, G(\bm{x}))\frac{\partial g_m}{\partial x_j}(\bm{x}) = \frac{\partial f_i}{\partial x_j}(\bm{x}, G(\bm{x})) + \sum_{k=1}^m \frac{\partial f_i}{\partial g_k}(\bm{x}, G(\bm{x}))\frac{\partial g_k}{\partial x_j}(\bm{x}) \end{eqnarray*} $$が得られる。$F$は連立表示されていたのを思い出せば、これを$F$全体に適用させて、行列とベクトルで次のように表示できる。
$$ \begin{equation} \label{equation: n-dim-implicit-1} \begin{pmatrix} \frac{\partial f_1}{\partial g_1}(\bm{x}, G(\bm{x})) & \cdots & \frac{\partial f_1}{\partial g_m}(\bm{x}, G(\bm{x})) \\ \vdots & \ddots & \vdots \\ \frac{\partial f_m}{\partial g_1}(\bm{x}, G(\bm{x})) & \cdots & \frac{\partial f_m}{\partial g_m}(\bm{x}, G(\bm{x})) \end{pmatrix} \begin{pmatrix} \frac{\partial g_1}{\partial x_j}(\bm{x}) \\ \vdots \\ \frac{\partial g_m}{\partial x_j}(\bm{x}) \end{pmatrix} = - \begin{pmatrix} \frac{\partial f_1}{\partial x_j}(\bm{x}, G(\bm{x})) \\ \vdots \\ \frac{\partial f_m}{\partial x_j}(\bm{x}, G(\bm{x})) \end{pmatrix} \end{equation} $$このとき、左辺の係数行列は$j$とは無関係な線形変換であり、m次元ベクトル$(\frac{\partial g_i}{\partial x_j}(\bm{x}))$に一律で掛けられる倍率である。陰関数$G(\bm{x})$の偏導関数$\frac{\partial G}{\partial x_j} \hspace{5pt} (1 \leq j \leq n)$を求めるには、この係数行列$\frac{\partial F}{\partial y_i} \hspace{5pt} (1 \leq i \leq m)$が正則(つまり行列式が0でない)であれば良い。実はこのような形の行列やベクトルには定義があるため、陰関数の偏導関数を得る前に少し補足を行う。
補足:勾配¶
ベクトル解析の分野となるので、概要を掴む程度に補足する。ベクトル解析における勾配とは、端的に言えばスカラー場$f$(我々が暮らす空間中の温度のように、空間の各点でスカラーがひとつ決まるようなn変数関数$f$のこと)に対して、$f$が最も大きく変化する方向を向き、その変化率と同じ大きさを持つベクトルのことで、$grad f$と表す。$grad f$は$n$次元スカラー場で、点$f(\bm{x} = (x_i))$を各変数方向に偏微分した$\frac{\partial f}{\partial x_1}, \cdots, \frac{\partial f}{\partial x_n}$を成分にもつベクトルで
$$ grad f = \begin{pmatrix} \frac{\partial f}{\partial x_1} \\ \vdots \\ \frac{\partial f}{\partial x_n} \end{pmatrix} $$のように定義される。
e.g. 3次の$grad f$¶
$$ grad f(x, y, z) = f_x(x, y, z)\begin{pmatrix} 1 \\ 0 \\ 0 \end{pmatrix} + f_y(x, y, z) \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix} + f_z(x, y, z) \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix} $$ここで、$f(x, y, z) = x + 3y + 5z$であるならば、$grad f = \begin{pmatrix}1 \\ 3 \\ 5 \end{pmatrix}$となり、$grad f$は$z$方向を向いている。
この例から、$grad f$は各変数の基本ベクトル方向に向いていると考えることができ、基本ベクトル$\bm{i}_n$を用いて
$$ grad f = \sum_{j=1}^n \bm{i}_j\frac{\partial f}{\partial x_j} $$のように表すこともできる。これにより、各変数方向に偏微分したというのが納得できたのではないだろうか。また、新たにベクトル微分演算子$\nabla$(ナブラ)を導入し定義を次とする。
$$ \nabla = \sum_{j=1}^n \bm{i}_j\frac{\partial}{\partial x_j} = \begin{pmatrix} \frac{\partial }{\partial x_1} \\ \vdots \\ \frac{\partial }{\partial x_n} \end{pmatrix} $$したがって、$grad f = \nabla f$ である。(以降は$\nabla f$を使う)
では、この$\nabla f$がなぜ$f$が最大となる方向を向くのかという話に入ろう。(この話が陰関数定理やラグランジュの未定乗数法を理解するために重要である)
$\nabla f$が$f$が最大となる方向を向く理由¶
先程のスカラー値関数$f(x, y, z) = x + 3y + 5z$という曲面が、$f(x, y, z) = c_1 \hspace{5 pt} (d_1 \in \mathbb{R})$を満たす点$(x, y, z)$によって出来る集合を考えよう。実はこのような集合はひとつの曲面を表し、等位面と呼ばれる。もちろん$f(x, y, z) = c_1, f(x, y, z) = c_2, \cdots, f(x, y, z) = c_n, \cdots$のように$f(x, y, z)$が決定するスカラーを変化させたとき、これらを満たす点$(x, y, z)$の集合はある種の層のようになる。これは図形的には、地形図に出てくる等高線のような形になるのだ。(地形図上で、同じ高さを結んだ線のことを等高線と呼んだ。つまり、地形図は$f(x, y, z)$で高さが求まるスカラー場である。) そして、この等位面はある点$(x, y, z)$におけるスカラーがただ1つに決まるので、異なる等位面どうしが交わることがないという重要な性質を持つ。
ここで、あるスカラー場$f(x, y, z) = c $の等位面における$\nabla f$を考えよう。この等位面のうち、点$\bm{r} = (x_0, y_0, z_0)$を適当に選び、$\bm{r}$が$\Delta \bm{r} = \begin{pmatrix} \Delta x_0, \Delta y_0, \Delta z_0 \end{pmatrix}$方向に微小変化すること、つまり$f(x_0 + \Delta x_0, y_0 + \Delta y_0, z_0 + \Delta z_0) - f(x_0, y_0, z_0)$を考える。このとき、$f(\bm{r}) = f(\Delta \bm{r}) = c$である。よって、$df = 0$となる。これは同等位面での点の移動であるから、高さが不変で、傾きが$0$になるということを言っている。よって、$f$が全微分可能という仮定のもと$df$を一次近似すれば、
$$ \begin{eqnarray*} f(x_0 + \Delta x_0, y_0 + \Delta y_0, z_0 + \Delta z_0) - f(x_0, y_0, z_0) &=& \frac{\partial f}{\partial x_0}\Delta x_0 + \frac{\partial f}{\partial y_0}\Delta y_0 + \frac{\partial f}{\partial z_0}\Delta z_0 \\ &=& \begin{pmatrix} \Delta x & \Delta y & \Delta z \end{pmatrix}\begin{pmatrix} \frac{\partial f}{\partial x_0} \\ \frac{\partial f}{\partial y_0} \\ \frac{\partial f}{\partial z_0} \end{pmatrix} \\ &=& \langle \Delta \bm{r}, \nabla f \rangle = 0 \end{eqnarray*} $$を得る。ここで、$\Delta \bm{r}$が示すのは、$\bm{r}$から$\Delta \bm{r}$への移動距離である。つまり、図形的には等位面$f(x, y, z) = 0$の$(x_0, y_0, z_0)$における接線となっている。したがって、$\nabla f$は接線に直交する法線ベクトルということを示している。例えば、円の方程式$f(x, y): x^2 + y^2 = c$において、$f(x, y) = 1, f(x, y) = 2, \cdots$のように等高線表示していくと、$\Delta \bm{r}$はある点$P$における円周の傾きを表し、$\nabla f$はそこに直交することになる。このことは$f(x, y)$が各点の$\nabla f$方向に広がることを示していると言える。つまり、$\nabla f$方向に関数の値が最も増加するのである。これが勾配という概念が$f$が最も大きくなる方向を表すということへの説明である。
勾配の理解において非常にわかりやすい資料(3章 勾配,傾き,gradient [新潟大学 山口研究室] )があったので、興味がある方はぜひ見てほしい。
方向微分¶
なお、一般的に、スカラー値関数$f$の点$\bm{a}$における$\bm{v} \in \mathbb{R}^n$方向への微分を、$\bm{v}$方向への方向微分という。実際に方向微分が行えるかは、方向微分係数の存在チェックをする必要があるが、ここでは割愛する。また、方向微分自体は$\nabla f$と$\Delta \bm{v}$の内積で表されるが、今回の等位面上の微小変化のようにすべてが$0$になるわけではなく、あくまでスカラー値関数のある点でのある方向への微小変化という概念であるから、その他のスカラー値も取ることに注意しよう。
補足: ヤコビ行列¶
スカラー値関数$f_i$を成分とする、多変数ベクトル値関数$f = \begin{pmatrix} f_1(x_1, \cdots, x_n) \\ \vdots \\ f_m(x_1, \cdots, x_n) \\ \end{pmatrix}$のヤコビ行列は、$f$の各成分の各軸方向への方向微分を並べてできる行列で
$$ J_f = D_{x}f(\bm{x}) = \frac{\partial f}{\partial \bm{x}} = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial f_m}{\partial x_1} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} = \begin{pmatrix} \nabla f_1 \\ \vdots \\ \nabla f_m \end{pmatrix} $$のように表される。(同様に、$y$で偏微分すれば、$D_{y}f$と表せる。)
また、ヤコビ行列は直交座標$\Longleftrightarrow$極座標の変換を考える上でも有用である。
$V = \mathbb{R}^2$で例を示そう。$x=r\cos\theta, y=r\sin\theta$とすると
$$ \begin{pmatrix} \frac{\partial x}{\partial r} & \frac{\partial x}{\partial \theta} \\ \frac{\partial y}{\partial r} & \frac{\partial y}{\partial \theta} \end{pmatrix} = \begin{pmatrix} \cos \theta & -r\sin\theta \\ \sin \theta & r\cos\theta \end{pmatrix} $$で直交座標と極座標の変換を表すこと出来る。
このヤコビ行列を用いれば、「陰関数定理の(3次以上の)多変数への拡張」における陰関数定理は、$F(\bm{a}, \bm{b}) = 0$かつ$det(D_{y}F(\bm{a}, \bm{b})) \neq 0$のとき、$b_i = g_i(\bm{a})$、$(\bm{a}, \bm{b})$の$\epsilon$-近傍$U$において、$\bm{x} \in U$に対し$f_i(x_1, \cdots, x_n, g_1(x_1, \cdots, x_n), \cdots, g_m(x_1, \cdots, x_n)) = 0 \quad (1 \leq i \leq m) \hspace{5pt} \Longrightarrow y_i = g_i(\bm{x})$ となる$G = (g_i)$が存在する。このとき式$(\ref{equation: n-dim-implicit-1})$の左辺は
$$ \frac{d G}{d \bm{x}} = - (D_{y}F(\bm{x}, \bm{y}))^{-1} D_{x}F(\bm{x}, \bm{y}) $$である。このように、一般の陰関数定理は、陰関数の接線の傾きをヤコビ行列を用いて表すことが出来る。ここまでで、ラグランジュの未定乗数法の理解のための道具は揃った。
ラグランジュの未定乗数法¶
$D \subset \mathbb{R}^2$を開集合とする。$f: D \to \mathbb{R}, g: D \to \mathbb{R}$を$C^1$級の関数とする。$g$の零点集合$S$を$S := \{(x, y) \in D \hspace{3pt} | \hspace{3pt} g(x, y) = 0\}$とする。このとき、点$(a, b) \in S$が$f$の$S$上で極値点を持つならば、次のいずれかが成り立つ。
(L 1): $\frac{\partial g}{\partial x}(a, b) = \frac{\partial g}{\partial y}(a, b) = 0 \quad $ (このような点$(a, b)$を曲線$g(x, y) = 0$の特異点という。)
(L 2): ある$\lambda \in \mathbb{R}$が存在して、 $$ \begin{pmatrix} \frac{\partial f}{\partial x}(a, b) \\ \frac{\partial f}{\partial y}(a, b) \end{pmatrix} = \lambda \begin{pmatrix} \frac{\partial g}{\partial x}(a, b) \\ \frac{\partial g}{\partial y}(a, b) \end{pmatrix} = \bm{0} $$ が成り立つ. (L 2') は次のように言い換えることもできる。
(L 2'): $L(x, y, \lambda) = f(x, y) - \lambda g(x, y)$ とおけば、ある$\lambda_0 \in \mathbb{R}$が存在して、 $$\hspace{5pt} \frac{\partial L}{\partial x}(a, b, \lambda_0) = \frac{\partial L}{\partial y}(a, b, \lambda_0) = \frac{\partial L}{\partial \lambda_0}(a, b, \lambda_0) = 0 $$
が成り立つ。
定理の補足
まず、点$(a, b)$が$f$の$S$上の極値点であるとは,点$(a, b) \in S$の近傍$U$が存在して,$S\cap U$上で$f$が最小値あるいは最大値を取るということを言っている。よって、最大/最小値は$S$上に存在する必要があるので、零点集合$S$、あるいはその関数$g(x, y) = 0$を拘束条件、束縛条件と言う。そして、条件(L 1)を満たす場合は陰関数定理を持ち出すことができない($F_y(x, y) \neq 0$という条件があったはず)ので、$(a, b)$が特異点の場合はラグランジュの未定乗数法を利用することができない。よって、定理の本筋は(L 2)であり、$(a, b)$が特異点でないとき、つまり$g(a, b)$が全微分可能なときに成立する。
注意として、ラグランジュの未定乗数法で得られるのは、極値をとる点であるための必要条件である。
証明
$g(x, y) = 0$かつ$g_y(x, y) \neq 0$と仮定すると、陰関数定理により点$(a, b) \in S$の近傍で陰関数$y = \varphi(x)$が存在し、
$$ b = \varphi(a), \hspace{5pt} \varphi'(a) = - \frac{g_x(a, b)}{g_y(a, b)} $$が成立し、$f(x, y) = f(x, \varphi(x))$と$f$は$x$の1変数関数で表される。$f$が$x = a$で極値をとれば、
$$ \begin{eqnarray*} f'(a) &=& f_x(a, \varphi(a)) + f_y(a, \varphi(a))\varphi'(a) \\ &=& f_x(a, b) + f_y(a, b) \cdot (-\frac{g_x(a, b)}{g_y(a, b)}) \\ &=& f_x(a, b) - \frac{f_y(a, b)}{g_y(a, b)}g_x(a, b) \\ &=& 0 \end{eqnarray*} $$ここで、$\frac{f_y(a, b)}{g_y(a, b)} = \lambda$とおけば、$f_x(a, b) - \lambda g_x(a, b) = 0$が得られる。$g_x(a, b) \neq 0$のとき$x$を$y$の関数として同様の論法で証明できる。ゆえに、$f_y(a, b) - \lambda g_y(a, b) = 0$. これらが成立する$\lambda$を$\lambda_0$とすれば、条件(L 2)の多変数ベクトル値関数
$$ L(x, y, \lambda_0) = \begin{cases} f_x(x, y) - \lambda_0 g_x(x, y) = 0 \\ f_y(x, y) - \lambda_0 g_y(x, y) = 0 \end{cases} $$が得られる。$\frac{\partial L}{\partial x}(a, b, \lambda_0) = \frac{\partial L}{\partial y}(a, b, \lambda_0) = 0$を示す。
$\frac{\partial L}{\partial x}, \frac{\partial L}{\partial y}$に関して$L$を展開すれば
$$ \begin{equation} \label{lagrange-multiplier-1} \frac{\partial f}{\partial x}(a, b) - \lambda_0 \frac{\partial g}{\partial x}(a, b) = \frac{\partial f}{\partial y}(a, b) - \lambda_0 \frac{\partial g}{\partial y}(a, b) = 0 \end{equation} $$により示される。$\frac{\partial L}{\partial \lambda_0}(a, b, \lambda_0) = 0$に関しても同様に$L$を展開すれば、$-g(a, b) = 0$のみが残り(L 2')の主張が証明される。(つまり、$\frac{\partial L}{\partial \lambda_0} = g(a, b)$である)
□
(L 2) $\Longleftrightarrow$ (L 2') も同様に示しておこう。先に(L 2') $\Longrightarrow$ (L 2)を示す。 式($\ref{lagrange-multiplier-1}$)を連立方程式で表示すると
$$ \begin{cases} \frac{\partial f}{\partial x}(a, b) - \lambda_0 \frac{\partial g}{\partial x}(a, b) = 0 \\ \frac{\partial f}{\partial y}(a, b) - \lambda_0 \frac{\partial g}{\partial y}(a, b) = 0 \end{cases} $$より、これを行列表示すれば
$$ \begin{equation} \label{lagrange-multiplier-2} \begin{pmatrix} \frac{\partial f}{\partial x}(a, b) \\ \frac{\partial f}{\partial y}(a, b) \end{pmatrix} = \lambda \begin{pmatrix} \frac{\partial g}{\partial x}(a, b) \\ \frac{\partial g}{\partial y}(a, b) \end{pmatrix} = \bm{0} \hspace{5pt} \Longleftrightarrow \hspace{5pt} \nabla f = \lambda \nabla g \end{equation} $$を得る。(L 2) $\Longrightarrow$ (L 2')はこれを逆に辿れば良い。式($\ref{lagrange-multiplier-2}$)について、$\nabla f$と$\nabla g$の関係は平行であることが分かる。(勾配が一致している) このことをより理解するために、次の図を見てもらいたい。
ラグランジュの未定乗数法の図形によるイメージ¶

この図はWikipedia から拝借したものである。
これはラグランジュの未定乗数法の$g(x, y) = c$上の$f$の極値を求める瞬間を図示している。
青い点線で囲われた楕円が勾配の補足で説明した等高線で、各$f(x, y) = d_i$を満たす$(x, y)$の集合である。赤い曲線が制約条件$g(x, y) = c$である。このとき、$g$が極値を取る(傾きが0になる)$f$上の点$(a, b)$において、陰関数定理により求めた$\phi$の傾きと$g$の傾きが一致する。($g$と$f$が接する)つまり、$\phi$と$g$の接線の法線(矢印で描かれているもの)$\nabla f$と$\nabla g$が
$$ \nabla f = \lambda \nabla g $$の関係で表されるということを言っている。逆に$g$と$f$が交差する点、この図では$f = d_2$と$f = d_3$において、それぞれの交点$(x, y)$で$f$を$g$の向かう方向に方向微分すると、その点が$d_2, d_3$上から外れてしまい、高さが変わってしまう。つまり、それぞれの等高線上で$g$の経路に沿った微分ができないので、この点では$f$が極値を持たないのである。
コードによるラグランジュの未定乗数法の解法¶
例題として、コードによるラグランジュの未定乗数法の解法を紹介する。
また、下にプロットした図は、青い曲面が目的関数f(x, y)、赤い線が拘束条件$g(x, y) = 0$を表しており、$g(x, y) = 0$上の赤い点でfが極値を取っている様子を表している。また、等高線表示したものもおまけとして描画した。
import numpy as np
import sympy as sy
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from IPython.display import display, HTML, Math
sy.init_printing()
def maxmaize_f(x, y):
return -x ** 2 + y ** 2 + 3
def constraint_f(x, y):
return x * 2 + 3 * y - 5
# g(x, y) = 0が定めるyについて陰関数y = φ(x)
def implicit_y(x):
return (-2 * x + 5) / 3
x, y, l = sy.symbols('x y λ')
# 目的関数
f = maxmaize_f(x, y)
# 制約条件
g = constraint_f(x, y)
# ラグランジュ関数
L = f - l * g
# 偏微分
dLx = L.diff(x)
dLy = L.diff(y)
dLl = L.diff(l)
# 連立方程式を解く
s = sy.solve([dLx, dLy, dLl])
display(Math(r'f(x, y) = %s' % (sy.latex(f))))
display(Math(r'g(x, y) = %s = 0' % (sy.latex(g))))
display(Math(r'L(x, y, λ) = %s' % (sy.latex(L))))
display(Math(r'\frac{\partial L}{\partial x} = %s' % (sy.latex(dLx))))
display(Math(r'\frac{\partial L}{\partial y} = %s' % (sy.latex(dLy))))
display(Math(r'\frac{\partial L}{\partial l} = %s' % (sy.latex(dLl))))
display(Math(r'極値(x, y): %s' % (sy.latex(s))))
def show_3D_plot(domain, maxmaize_f, constraint_f,
implicit_y, extream_val, counter=False, angle=None, before_show=None):
fig = plt.figure(figsize=(8, 6))
ax = Axes3D(fig)
X, Y = np.meshgrid(domain, domain)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
if counter:
ax.contour(X, Y, maxmaize_f(X, Y), alpha=0.6)
else:
ax.plot_surface(X, Y, maxmaize_f(X, Y), alpha=0.6, color="blue")
# 制約条件
ax.plot(domain, implicit_y(domain), [maxmaize_f(x, implicit_y(x)) for x in domain], color="red")
# 極値点
ax.scatter([extream_val[0]],
[extream_val[1]], [maxmaize_f(float(extream_val[0]), float(extream_val[1]))], color='red')
if angle is not None:
ax.view_init(angle[0], angle[1])
if before_show is not None:
before_show(ax)
plt.show()
show_3D_plot(domain=np.arange(-4, 4, 0.1),
maxmaize_f=maxmaize_f,
constraint_f=constraint_f,
implicit_y=implicit_y,
extream_val=[s[x], s[y]],
angle=(50, 300))
show_3D_plot(domain=np.arange(-4, 4, 0.1),
maxmaize_f=maxmaize_f,
constraint_f=constraint_f,
implicit_y=implicit_y,
extream_val=[s[x], s[y]],
counter=True,
angle=(50, 300))


# 𝑓_𝑥(𝑎,𝑏)−𝜆𝑔_𝑥(𝑎,𝑏) = 0の確認
f.diff(x).evalf(subs={x: s[x]})-(f.diff(y).evalf(subs={y: s[y]}) / g.diff(y))*g.diff(x)
主成分分析のアルゴリズム¶
ラグランジュの未定乗数法の理解がある程度進んだところで、いよいよ主成分分析のアルゴリズムに入ろう。
記号、式の定義¶
- ${}^t\bm{a}$を$\bm{a}$の行ベクトル、${}^t A$を$A \in M_n(\mathbb{R})$の転置行列とする
- $\bm{a}, \bm{b} \in \mathbb{R}^n$の内積を$\langle \bm{a}, \bm{b} \rangle = {}^t\bm{a}\bm{b} = a_1b_1 + \cdots + a_nb_n$とする
- $Var(\bm{x})$は$\bm{x}と\bm{y}$の分散(Variance)、$Cov(\bm{x}, \bm{y})$は$\bm{x}と\bm{y}$の共分散(Covariance)を表す
- $Cov(\bm{x}, \bm{x}) = Var(\bm{x}), Cov(\bm{x}, \bm{y}) = Cov(\bm{y}, \bm{x})$であることを思い出そう
主成分分析のアルゴリズム¶
- データを標準化(このとき、データの重心が決まる。)
- 重心を原点としてデータの分散が最大となる方向(ベクトル)$w_1$を見つける。これを第一主成分と呼ぶ。
- $w_1$を基底とし、$w_1$に直交(内積が0になる)し、かつ分散が最大となる方向を$w_2$とする。これは第二主成分になる。
- 以降、2-3をデータ行列と同様のランク数の主成分を得るまで繰り返し行う。(第一主成分、第二主成分を、第$(i, i+1, \cdots , p)$主成分のように置き換える)
ここまでが主成分を得るアルゴリズムである。以降、
- それぞれの主成分における寄与率を計算し、その累積寄与率がだいたい80%を超えるまでを目安とし、第$r$番目$(r \leq p)$までの主成分を選択する($r = p$のとき次元削減は行われない)
- 主成分得点を計算し、因子負荷量と合わせてデータを考察する
のように分析を行う
主成分の導出¶
変数の個数がp、サンプルサイズがnの入力データを$p\times n$行列
$$ \bm{A} = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{p1} & a_{p2} & \cdots & a_{pn} \end{pmatrix} $$とする。
1. データを標準化¶
ひとまずのゴールとして、データの分散が最大となる方向を求めよう。このような方向を以降は第一主成分と呼ぶ。これを行うために、平均が0、分散が1になるようにデータを標準化する。これは、データの重心(各軸の平均値)を原点として、データを平行移動し、元のデータが平均からどれほど離れいているかという新たな指標でデータを変換するような処理となる。
標準化された行列$A$を
$$ U = (\bm{u}_1, \bm{u}_2, \cdots, \bm{u}_n) = standardization(A) $$とする。($standardization$は$(a_j)$の平均が0、分散が1になるように標準化する関数)
2. 重心を原点としてデータの分散が最大となる方向を見つける¶
これを考えるために以降は計量ベクトル空間で考えていこう。ここで、データの分散が最大となるということは、データの重心(原点)から伸びる適当な単位ベクトル$\bm{a} \in \mathbb{R}^p$を取ってきて、$\bm{a}$に$U$の各ベクトル$\bm{u}_i$を直交射影したときのベクトルが最大になるということである。ここで、$\bm{a}$は単位ベクトルであるから、
$$ w_1 = \sum_{i=1}^n \langle \bm{a}, \bm{u}_i \rangle $$を最大化することを考えれば良い。また、ここで$\bm{a}を$単位ベクトルにした理由として、正射影ベクトルを最大化させたいのだから、$\bm{a}$に制限を設けないと無限に大きな内積となってしまうからである。そもそもこれが1でなければ、データの分散をきちんと反映しているとは言えず、分散の水増しになってしまう。言葉だけでの理解は難しいと思うので、図を用意した。
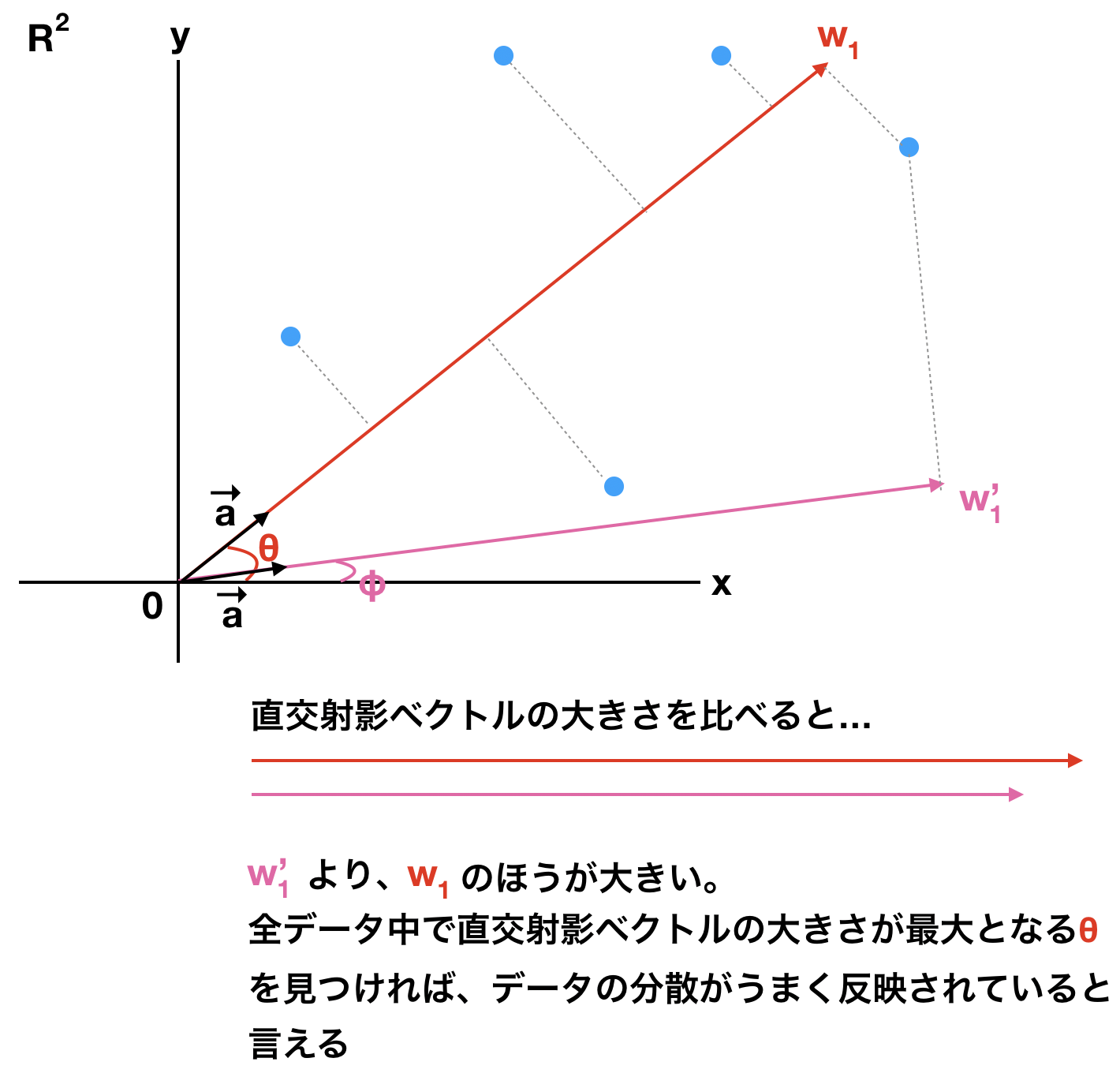
この図中の$\bm{w}_1$は$w_1$の$\bm{a}$方向のベクトルである。このようなベクトルを得るために、$U$の分散を考える。一般的な分散の定義は次式で与えられる。
$\bm{x} \in \mathbb{R}^n, \quad \overline{\bm{x}}$を$\bm{x}$の平均とする。
$$ Var(\bm{x}) = \frac{1}{n} \sum_{i=1}^n (x_i - \overline{\bm{x}})^2 $$ただし、すでにデータは標準化されているので、今回は
$$ Var(\bm{x}) = \frac{1}{n} \sum_{i=1}^n x_i^2 $$でよい。これを$w_1$に適用しよう。分散の定義式における$\bm{x}$の各成分$(x_1, \cdots,x_n)$を今回のデータに置き換えれば次のように表される。
$$ w_{i1} = a_1u_{i1} + a_2u_{i2} + \cdots a_pu_{ip} = \langle \bm{a}, \bm{u}_i \rangle $$よって、$\bm{w}_1$を使った成分表示では
$$ \bm{w}_1 = \begin{pmatrix} w_{11} \\ w_{21} \\ \vdots \\ w_{p1} \end{pmatrix} $$これより、$w_1$の分散は次のようになる。
$$ \begin{eqnarray*} V_{w_1} &=& \frac{1}{n} w_{i1}^2 \\ &=& \frac{1}{n-1} \sum_{i,j=1}^n \langle \bm{a}, \bm{u}_i \rangle \langle \bm{u}_j, \bm{a} \rangle \\ &=& \frac{1}{n-1} \sum_{i,j=1}^n {}^t\bm{a}\bm{u}_i {}^t\bm{u}_j\bm{a} \\ &=& \langle \bm{a} \left( \frac{1}{n-1}\sum_{i,j=1}^n \langle \bm{u}_i, \bm{u}_j \rangle \right), \bm{a} \rangle \\ &=& \langle \bm{a}S, \bm{a} \rangle \end{eqnarray*} $$ここで、最後に導出された行列$S$は共分散行列(相関行列)と呼ばれる形になっている。すなわち
$$ S = \begin{pmatrix} Var(\bm{u}_1) & Cov(\bm{u}_1, \bm{u}_2) &\cdots & Cov(\bm{u}_1, \bm{u}_p) \\ Cov(\bm{u}_2, \bm{u}_1) & Var(\bm{u}_2) &\cdots & Cov(\bm{u}_2, \bm{u}_p) \\ \vdots & \vdots & \ddots & \vdots \\ Cov(\bm{u}_p, \bm{u}_1) & Cov(\bm{u}_p, \bm{u}_2) &\cdots & Var(\bm{u}_p) \end{pmatrix} $$$i = j$のとき単位ベクトルの分散を求めることになるから、対角成分はすべて1となる。共分散行列$S$は実対称行列で
- ${}^tS = S$
- $\overline{S} = S$ ($\overline{S}$は$S$の複素共役)
が成り立つ。
$S$が実対称行列なので、$V_{w_1} = \langle \bm{a}S, \bm{a} \rangle$は$S$の$\bm{a}$による二次形式となっている。
補足: 二次形式¶
実対称行列$A = (a_{ij}) \in M_n(\mathbb{R})$と $\bm{x} = \begin{pmatrix} x_1 \\ \vdots \\ x_n \end{pmatrix}$に対して、関数
$$ \langle \bm{x}A, \bm{x} \rangle = \sum_{i, j=1}^n a_{ij}x_ix_j $$を$A$に関する2次形式という。$i=j$のときに、$x_ix_j = x_i^2$となるため、二次の多項式の形になる。
例: 3次元の場合
実対称行列$ A = \begin{pmatrix} a & p & r \\ p & b & q \\ r & q & c \end{pmatrix} $に対して、その二次形式を$\bm{v} = \begin{pmatrix} x \\ y \\ z \end{pmatrix}$の関数とすれば次になる。
$$ <\bm{v}A, \bm{v}> = ax^2 + by^2 + cz^2 + 2pxy + 2rxz + 2qyz $$このように、すべての項が$k \cdot x_ix_j$のような二次の形になることから、二次形式と呼ばれている。
ラグランジュの未定乗数法の登場¶
今我々は、$V_{w_1}$が最大となるような$\bm{a}$を求めようとしていた。つまり、関数$V_{w_1}$が最大となる点が$\bm{a}$ということである。これを求めるためにいよいよ登場するのがラグランジュの未定乗数法である。なぜなら、$V_{w_1}$は定義域を決めないことには関数の値が無限に大きくなってしまうので、制約条件を設定する必要がある。今我々が知りたいのは方向だけであり、求めたい$\bm{a}$は単位ベクトル、つまりノルムが1であったことを思い出そう。
よって、制約条件を
$$ g(\bm{a}) = a_1^2 + a_p^2 -1 = \langle \bm{a}, \bm{a} \rangle -1 = 0 $$に設定する。これは、次元に応じて、単位円、単位球、$n次元超球$の方程式と変化する。(原点からの$\theta$を求めたいのと、$\bm{a}$のノルムが1という制約があるのだから、単位球の方程式を制約条件とするのは腑に落ちるだろう。)
もちろん、目的関数は
$$ V_{w_1} = \langle \bm{a}S, \bm{a} \rangle $$である。$f(\bm{a}) = V_{w_1}$として、ラグランジュ関数を
$$ \begin{eqnarray*} L(\bm{a}, \lambda) &=& f(\bm{a}) - \lambda g(\bm{a}) \\ &=& \langle \bm{a}S, \bm{a} \rangle - \lambda(\langle \bm{a}, \bm{a} \rangle - 1) \end{eqnarray*} $$とおく。これを$\bm{a}$で微分して(イメージできなければ、$(a_i)$での微分を連立表示しよう)、$0$とおくと
$$ \begin{eqnarray*} \frac{\partial L}{\partial \bm{a}} &=& 2S\bm{a} - 2\lambda\bm{a} = S\bm{a} - \lambda\bm{a} = 0 \\ &\Longleftrightarrow& S\bm{a} = \lambda\bm{a} \end{eqnarray*} $$の固有値問題を得る。上式に${}^t\bm{a}$をかければ
$$ \begin{eqnarray*} \langle \bm{a}S, \bm{a} \rangle &=& \lambda \\ &\Longleftrightarrow& \lambda = V_{w_1} \end{eqnarray*} $$を得る。これはもともと最大化したかった$w_1$の分散そのものに他ならない。つまり、$\bm{a}$は固有値($w_1$の最大の分散)$\lambda$に対応する固有ベクトルである。この固有ベクトルが分散を最大化するための「方向」となる。$\bm{a}$が定まったことにより、$w_1$が第一主成分となった。
第二、第三主成分の導出¶
第二主成分も第一主成分と同様に適当な基底$\bm{b} \in \mathbb{R}^n$を取ってくる。第二主成分を
$$ w_2 = \sum_{i=1}^p \bm{b}\bm{u}_i $$のように定義する。この$w_2$の分散を$w_1$同様
$$ \begin{eqnarray*} V_{w_2} &=& \frac{1}{n} w_{i2}^2 \\ &=& \langle \bm{b}S, \bm{b} \rangle \end{eqnarray*} $$と定義する。$V_{w_2}$の最大値をラグランジュの未定乗数法によって求める。制約条件は$w_1$同様に$g(\bm{a}) = a_1^2 + a_p^2 -1 = \langle \bm{a}, \bm{a} \rangle -1 = 0 $を用いる。また、$w_2$は$w_1$に直交(つまり無相関)するというもう一つの条件もあるので、これも制約条件として設定しなければいけない。これまで、ラグランジュの未定乗数法は制約条件が一つだけだったが、実は制約条件を複数個設定できる。$g_i$を複数制約条件としてこれを一般化すると
$$ L(\bm{x}, \bm{\lambda}) = f(\bm{x}) - \lambda_1 g_1(\bm{x}) - \lambda_2 g_2(\bm{x}) - \cdots - \lambda_n g_n(\bm{x}) $$である。なお、$w_2$と$w_1$が直交する条件は、
$$ \langle \bm{w}_1, \bm{w}_2 \rangle = \sum_{i=1}^p \langle a_i\bm{x}_i, b_i\bm{x}_i \rangle = 0 $$である。したがって、第二の制約条件は$\langle \bm{a}, \bm{b} \rangle = 0$である。これらをもとにラグランジュ関数を
$$ L(\bm{b}, \lambda, \mu) = \langle \bm{b}S, \bm{b} \rangle - \lambda(\langle \bm{b}, \bm{b} \rangle - 1) - \mu\langle \bm{a}, \bm{b} \rangle $$とおいて、$\bm{b}$で微分して0とおくと
$$ \frac{\partial f}{\partial \bm{b}} = 2S\bm{b} - 2\lambda\bm{b} - \mu\bm{a} = 0 $$を得る。上式に${}^t\bm{a}$をかければ
$$ 2\langle \bm{a}S, \bm{b} \rangle - 2\lambda \langle \bm{a}, \bm{b} \rangle - \mu\langle\bm{a}, \bm{a} \rangle = 0 $$となり、$\langle \bm{a}S, \bm{b} \rangle = 0, \langle \bm{a}, \bm{b} \rangle = 0, \langle\bm{a}, \bm{a} \rangle = 1$より、$\mu = 0$が導かれる。したがって、
$$ S\bm{b} = \lambda\bm{b} $$より、またしても固有値問題を得る。$\bm{b}$が第二主成分の方向である。
このように第三主成分以降は、ラグランジュ関数の制約条件をこれまで得られた固有ベクトルに直交するように設定すると、$\lambda_1$以外の未定乗数がすべて0となり、最大値を得られるという仕組みである。これは実は共分散行列$S$の固有値問題そのものであることを言っている。つまり、共分散行列$S$の特性多項式
$$ det(\lambda E - S) = \begin{vmatrix} \lambda - Var(\bm{u}_1) & -Cov(\bm{u}_1, \bm{u}_2) &\cdots & -Cov(\bm{u}_1, \bm{u}_p) \\ -Cov(\bm{u}_2, \bm{u}_1) & \lambda - Var(\bm{u}_2) &\cdots & -Cov(\bm{u}_2, \bm{u}_p) \\ \vdots & \vdots & \ddots & \vdots \\ -Cov(\bm{u}_p, \bm{u}_1) & -Cov(\bm{u}_p, \bm{u}_2) &\cdots & \lambda - Var(\bm{u}_p) \end{vmatrix} = 0 $$を解いて得られた$S$の固有値$\lambda_i$を大きい順に並べると、これらの固有ベクトルが第i主成分に対応することになる。このメカニズムを知れば、ラグランジュの未定乗数法を用いることなく共分散行列の固有値・固有ベクトルを求めることが主成分を導出することと同値になる。これが主成分分析がデータの共分散行列の固有値問題を解くことで行われるカラクリである。
主成分を新座標系としてデータを線形変換する¶
この要領で得た主成分が新座標系での軸となる。ここで、主成分分析の本来の目的であった次元削減を行いたいが、その指標として使うものが寄与率である。 寄与率は各主成分に対して求まるその主成分のデータの説明度の割合で、各主成分に対応する固有値を固有値すべての合計で割ることで得られる。すべての寄与率を足しあわせると$100$となり、データの説明度が$100$%となる仕組みだ。このとき、寄与率の合計(累積寄与率)が80%を超えることを目的に、主成分を選んでいくと次元を$\mathbb{R}^m (m \leq n)$に落とすことが出来る。この選ばれたm個の主成分とデータ行列をかけ合わせる線形変換を施すことで、元のデータの座標が新座標系に移されるという仕組みである。次元が削減される理由は、すべての主成分が直交していることに由来する。つまり、選ばれた$m$個の次元は$m+1$以降の次元を表現できないということである。
以下は、この変換を$\mathbb{R}^3 \to \mathbb{R}^2$で行うイメージ図である。
|
|
|---|
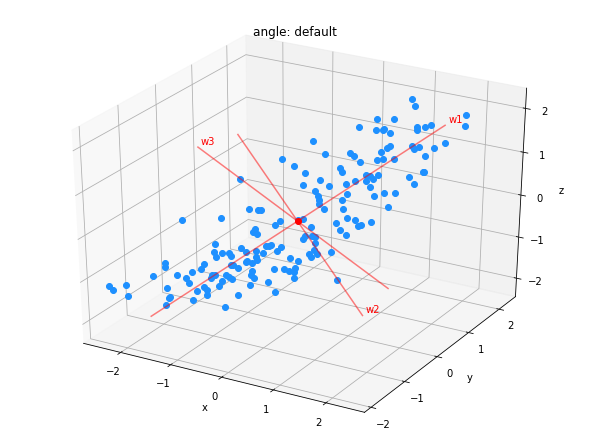 |
|
|
|---|
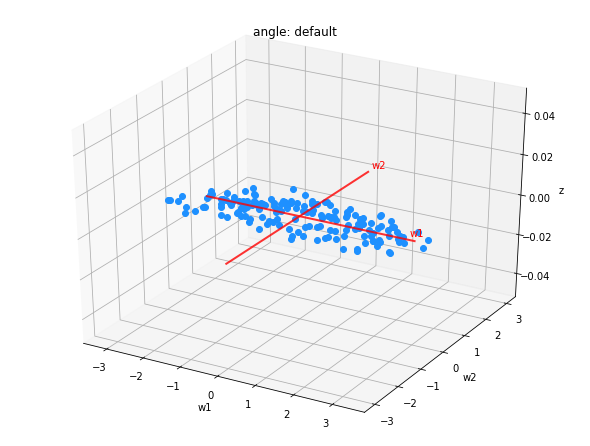 |
Pythonによる主成分分析の実装¶
理論だけだとやはり理解が難しいかと思うので、実際に説明した理論をPythonで実装して理解を深めていこう。
データセットは、https://statistics.co.jp/reference/statistical_data/statistical_data.htm の5.成績のデータを適当に3次元にしたものを利用
import math
import pandas as pd
sy.init_printing()
original_df = pd.read_csv("./seiseki.csv")
original_df = original_df.drop(["shakai", "taiiku", "ongaku", "gika", "bijutu", "rika"], axis=1)
original_df = original_df.rename(columns={"kokugo": "japanese", "sugaku": "math", "eigo": "english"})
original_df
標準化¶
normalized_df = (original_df - np.mean(original_df, axis=0)) / np.std(original_df, axis=0)
print("平均:", int(normalized_df.japanese.mean()), int(normalized_df.math.mean()), int(normalized_df.english.mean()))
print("分散:", np.var(normalized_df.japanese), np.var(normalized_df.math), np.var(normalized_df.english))
normalized_df
データのプロット¶
赤い点がデータの重心である
from matplotlib.text import Annotation
from mpl_toolkits.mplot3d.proj3d import proj_transform
class Annotation3D(Annotation):
def __init__(self, text, xyz, *args, **kwargs):
super().__init__(text, xy=(0,0), *args, **kwargs)
self._xyz = xyz
def draw(self, renderer):
x2, y2, z2 = proj_transform(*self._xyz, renderer.M)
self.xy=(x2,y2)
super().draw(renderer)
def _annotate3D(ax,text, xyz, *args, **kwargs):
'''Add anotation `text` to an `Axes3d` instance.'''
annotation= Annotation3D(text, xyz, *args, **kwargs)
ax.add_artist(annotation)
setattr(Axes3D,'annotate3D',_annotate3D)
def show_plot(data, angle = None, pca_components=None, n_pc=1, should_show_center_point=True, before_show=None, vector_scale=3):
fig = plt.figure(figsize=(8, 6))
ax = Axes3D(fig)
ax.set_xlabel("japanese")
ax.set_ylabel("math")
ax.set_zlabel("english")
ax.plot(data[0], data[1], data[2], marker="o", linestyle='None', c="dodgerblue")
if should_show_center_point:
ax.plot([np.mean(data[0])], [np.mean(data[1])], [np.mean(data[0])], marker="o", linestyle='None', color="r")
if pca_components is not None:
p = pca_components * vector_scale
for i in range(n_pc):
ax.plot(
[-p[i][0], p[i][0]],
[-p[i][1], p[i][1]],
zs=[-p[i][2], p[i][2]],
color = 'r',
alpha = 0.5)
ax.annotate3D(f'w{i+1}',
p[i],
xytext=(3,3),
textcoords='offset points',
color="r")
if angle:
ax.view_init(angle[0], angle[1])
plt.title(f"angle: elev={angle[0]}, azim={angle[1]}")
else:
plt.title(f"angle: default")
if before_show is not None:
before_show(ax)
plt.show()
show_plot([normalized_df.japanese, normalized_df.math, normalized_df.english])

共分散行列¶
S = np.dot(normalized_df.T, normalized_df) / float(normalized_df.shape[0])
display(Math(r'S = %s' % (sy.latex(sy.Matrix(S)))))
# 実対称行列であることの判定
print("S == S.T:", np.array_equal(S, S.T))
print("S == S.conjugate():", np.array_equal(S, S.conjugate())) # 複素共役
Sの二次形式¶
def maxmaize_f(x, y, z):
return x**2 + y**2 + z**2 + (2 * S[0][1] * x * y) + (2 * S[0][2] * x * z) + (2 * S[1][2] * y * z)
# a_1, a_2, a_3をそれぞれx, y, zとおく
x, y, z, l = sy.symbols('x y z λ')
# Sの二次形式
f = maxmaize_f(x, y, z)
display(Math(r'f(x, y, z) = %s' % (sy.latex(f))))
ラグランジュの未定乗数法¶
def constraint_f(x, y, z):
return x**2 + y **2 + z**2 -1
# 制約条件
g = constraint_f(x, y, z)
display(Math(r'g(x, y, z) = %s = 0' % (sy.latex(g))))
# ラグランジュ関数
L = f - l * g
display(Math(r'L(x, y, z, \lambda) = %s' % (sy.latex(L))))
# xでLを偏微分
dx = L.diff(x)
display(Math(r'\frac{\partial L}{\partial x} = %s' % (sy.latex(dx))))
# yでLを偏微分
dy = L.diff(y)
display(Math(r'\frac{\partial L}{\partial y} = %s' % (sy.latex(dy))))
# zでLを偏微分
dz = L.diff(z)
display(Math(r'\frac{\partial L}{\partial z} = %s' % (sy.latex(dz))))
# λでLを偏微分
dl = L.diff(l)*-1
display(Math(r'\frac{\partial L}{\partial \lambda} = %s' % (sy.latex(dl))))
# 連立方程式を解く
extream_value_candidates = sy.solve([dx, dy, dz, dl])
def value_without_infinitesimal(sympy_value):
if type(sympy_value) == sy.numbers.Add:
return sympy_value.args[0]
else:
return sympy_value
P = []
for evc in extream_value_candidates:
p = {
x: value_without_infinitesimal(evc[x]),
y: value_without_infinitesimal(evc[y]),
z: value_without_infinitesimal(evc[z]),
l: value_without_infinitesimal(evc[l])
}
P.append(p)
display(p)
ラグランジュの未定乗数法を解くことで、このように6つの解が得られた。($\lambda$は未定乗数で、$x, y, z$が経路$g = 0$上の$f$の極値点)これらを$\lambda$でグルーピングすれば、解は正負の異なる3種類に類別できる。(制約条件が単位球であることより)もちろん、この条件下では各極値点の内いずれを選んでも構わない。実対称行列の固有値・固有ベクトルに対応させるために無作為に3つを選び、これらを$\lambda$の大きい順に順番に並べてベクトル表示したものが以下である。各ベクトルのノルムが1となることも確認しておこう。
def norm(vec):
return math.sqrt(np.dot(vec, vec))
# λを大きい順に並べる
e_val = np.array([P[1][l], P[5][l], P[3][l]]).astype(float)
# λに対応するベクトル
e_vec = np.array([
[P[1][x], P[1][y], P[1][z]],
[P[5][x], P[5][y], P[5][z]],
[P[3][x], P[3][y], P[3][z]]
]).astype(float)
display(Math(r'\lambda_1 = %s' % (sy.latex(e_val[0]))))
display(Math(r'\bm{v}_1 = %s' % (sy.latex(sy.Matrix(e_vec[0])))))
display(Math(r'||\bm{v}_1|| = %s' % (sy.latex(norm(e_vec[0])))))
display(Math(r'\lambda_2 = %s' % (sy.latex(e_val[1]))))
display(Math(r'\bm{v}_2 = %s' % (sy.latex(sy.Matrix(e_vec[1])))))
display(Math(r'||\bm{v}_2|| = %s' % (sy.latex(norm(e_vec[1])))))
display(Math(r'\lambda_3 = %s' % (sy.latex(e_val[2]))))
display(Math(r'\bm{v}_3 = %s' % (sy.latex(sy.Matrix(e_vec[2])))))
display(Math(r'||\bm{v}_2|| = %s' % (sy.latex(norm(e_vec[2])))))
これらが$S$の固有値問題となるかを確認してみよう。numpyのlinalg.eigを使って固有値・固有ベクトルを求めたものが次である。
e_val_confirm, e_vec_confirm = np.linalg.eig(S)
e_vec_confirm = e_vec_confirm.T
print(e_val_confirm)
print(e_vec_confirm)
表示上の桁数は異なるものの、e_valとe_val_confirm、e_vecとe_vec_confirmが一致していることが確認できる。よって$w_i$の分散を最大化させることが、共分散行列の固有値・固有ベクトルを求めることに帰結した。
寄与率 (Contribution rate)¶
p = np.sum(e_val)
c1 = e_val[0]/p
c2 = e_val[1]/p
c3 = e_val[2]/p
display(Math(r'\frac{\lambda_1}{p} = %s' % (sy.latex(c1))))
display(Math(r'\frac{\lambda_2}{p} = %s' % (sy.latex(c2))))
display(Math(r'\frac{\lambda_3}{p} = %s' % (sy.latex(c3))))
第二種成分までの累積寄与率が$93.5%$を超えているので、このデータは二次元で十分に説明できる。よって、データを$\mathbb{R}^3 \to \mathbb{R}^2$に射影する。まず、第1主成分$w_1$、第2主成分$w_2$, 第3主成分$w_3$を求め、そこからさらに主成分得点を求める。
主成分得点¶
x, y, z = sy.symbols('x y z')
def principal_component(p, x, y, z):
return p[0] * x + p[1] * y + p[2] * z
w1 = principal_component(e_vec[0], x, y, z)
w2 = principal_component(e_vec[1], x, y, z)
w3 = principal_component(e_vec[2], x, y, z)
display(Math(r'w_1 = %s' % (sy.latex(w1))))
display(Math(r'w_2 = %s' % (sy.latex(w2))))
display(Math(r'w_3 = %s' % (sy.latex(w3))))
pc_score_df = pd.DataFrame({
"pc1": principal_component(e_vec[0], normalized_df.japanese, normalized_df.math, normalized_df.english),
"pc2": principal_component(e_vec[1], normalized_df.japanese, normalized_df.math, normalized_df.english),
"pc3": principal_component(e_vec[2], normalized_df.japanese, normalized_df.math, normalized_df.english)
})
print(pc_score_df.dtypes)
pc_score = np.array(pc_score_df)
pc_score_df
第$i$主成分の図形的な意味¶
第一主成分は分散が最大となる向き(ベクトル)を線形結合で表したものである。第二主成分は第一主成分に直交し、第三主成分は第一主成分と第二主成分に直交する。($w_i$のノルムは1となるので、図では見やすいようにスカラー倍していることに注意)
show_plot([normalized_df.japanese, normalized_df.math, normalized_df.english], pca_components=e_vec, n_pc=3)

$w_1, w_2$を新たな軸として線形変換($\mathbb{R}^3 \to \mathbb{R}^2$)する¶
def before_show(ax):
ax.set_xlabel("w1")
ax.set_ylabel("w2")
ax.set_zlabel("z")
ax.plot(
[-2.5, 3],
[0, 0],
zs=[0, 0],
color="r",
linewidth=2,
alpha=0.8)
ax.plot(
[0, 0],
[-3, 3],
zs=[0, 0],
color="r",
linewidth=2,
alpha=0.8)
ax.annotate3D(f'w2',
[0, 3, 0],
xytext=(3,3),
textcoords='offset points',
color="r")
ax.annotate3D(f'w1',
[2.8, 0, 0],
xytext=(3,3),
textcoords='offset points',
color="r")
show_plot([pc_score_df.pc1, pc_score_df.pc2, np.zeros(166)],
vector_scale=2,
should_show_center_point=False,
before_show=before_show)

この図を$x, y$平面に対して水平に見たものが次の図である。
def before_show(ax):
ax.set_xlabel("w1")
ax.set_ylabel("w2")
ax.set_zlabel("z")
show_plot([pc_score_df.pc1, pc_score_df.pc2, np.zeros(166)], should_show_center_point=False, angle=(0, 135), before_show=before_show)

このように、z軸で取る値がすべて$0$になっており、次元削減がなされていることが確認できる。3D表示だとかえって見ずらいので、これを2D表示することにしよう。
第二主成分までの主成分得点の散布図¶
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(1, 1, 1)
ax.spines['left'].set_position('center')
ax.spines['bottom'].set_position('center')
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
plt.scatter(pc_score_df.pc1, pc_score_df.pc2)
ax.set_ylabel("pc2")
ax.set_xlabel("pc1")
ax.xaxis.set_label_coords(0.5, 0)
ax.yaxis.set_label_coords(0, 0.5)
plt.title("Sekseki Principal Component Score")
plt.show()

因子負荷量¶
import seaborn as sns
features = ["japanese", "math", "english"]
components = pd.DataFrame(
e_vec,
columns=features,
index=["pc{}".format(x + 1) for x in range(len(features))]
)
fig = plt.figure()
ax = fig.add_subplot(111)
sns.heatmap(components,
cmap='Blues',
annot=True,
annot_kws={'size': 14},
fmt='.2f',
xticklabels=features,
yticklabels=['PC1', 'PC2', 'PC3'],
ax=ax)
plt.show()

散布図に因子負荷量を表示¶
def biplot(score, coeff, labels):
plt.figure(figsize=(12,8))
xs = score[:,0]
ys = score[:,1]
n = coeff.shape[0]
arrow_scale = 1
plt.scatter(xs, ys)
for i in range(n):
plt.arrow(0, 0,
coeff[i,0] * arrow_scale,
coeff[i,1] * arrow_scale,
color = 'r',
head_width=0.05,
head_length=0.05,
alpha = 0.5
)
plt.text(coeff[i,0]* arrow_scale* 1.1, coeff[i,1] * arrow_scale * 1.1, labels[i], color = 'r')
plt.xlabel("PC{}".format(1))
plt.ylabel("PC{}".format(2))
plt.grid()
biplot(pc_score[:,0:2], e_vec[0:2, :].T, labels=["japanese", "math", "english"])
plt.show()

データに関する考察はしないが、sklearnなどを使わずにPCAを実装する方法を紹介した。以上で主成分分析に関する解説を終わりにする。